Tech Blog
How can we represent images, like sentences, words, and letters?
In this technical blog, I will summarize a ViT, a vision transformer, which consists of image patching, position embedding, multi-attention head, feed forward networks with GLU, and also a little bit about optimization and training to give the whole picture.
The standard Transformer receives as input a 1D sequence of token embeddings. To handle 2D images, we reshape the imagex ∈ R^(H×W×C)into a sequence of flattened 2D patchesx_p ∈ R^(N×(P²·C)), where(H, W)is the resolution of the original image,Cis the number of channels,(P, P)is the resolution of each image patch, andN = HW / P²is the resulting number of patches.
The Transformer keeps a constant latent sizeDthrough all of its layers, so we flatten the patches and map toDdimensions with a trainable linear projection. We refer to the output of this projection as the patch embeddings.
Source: Dosovitskiy et al., 2020
1. Patchify: turning images into token sequences
Equation (1): Token initialization and embedding
z₀ = [xclass; xₚ¹E; xₚ²E; ...; xₚᴺE] + Epos
This equation describes how a 2D image is converted into a 1D sequence of vectors that a Transformer can process.
xₚⁱ (output of patchify): raw flattened patches. In a 4×4 example, each patch is a 1D vector of 16 raw pixel values.
The interactive tool below lets you vary image size, patch size, and channels so you can see how token count and dimensions change in practice.
Open patchify explainer in a new tab
Show patchify implementation (PyTorch)
def patchify(x: torch.Tensor, patch_size: int) -> torch.Tensor:
"""Convert images to flattened non-overlapping patch tokens.
Args:
x: Image batch with shape (batch_size, channels, height, width).
patch_size: Side length of each square patch.
Returns:
Tensor with shape (batch_size, num_patches, channels * patch_size * patch_size).
"""
batch_size, channels, height, width = x.shape
if height % patch_size != 0 or width % patch_size != 0:
raise ValueError("Image height and width must be divisible by patch_size")
patches_h = height // patch_size
patches_w = width // patch_size
x = x.reshape(batch_size, channels, patches_h, patch_size, patches_w, patch_size)
x = x.permute(0, 2, 4, 1, 3, 5).contiguous() # permute() changes view order; contiguous() fixes memory layout
return x.reshape(batch_size, patches_h * patches_w, channels * patch_size * patch_size)This second interactive block focuses only on patch embedding and positional embedding, showing the exact transition from C × P × P raw patch vectors to D-dimensional projected tokens.
Open patch embedding and positional embedding explainer in a new tab
E (linear projection): the projection layer (e.g. nn.Linear(16, D)) that maps each raw patch into a higher-dimensional feature vector of size D.
xclass (class token): a learnable vector of size D prepended to the sequence to aggregate global image information through self-attention.
N patches, increasing sequence length from N to N+1.
Epos (positional embeddings): a learnable matrix of size (N+1)×D added to tokens to preserve spatial awareness.
Show patch projection + positional embedding implementation (PyTorch)
# Patch projection and learned positional encoding from ViT.
class PatchEmbed(nn.Module):
def __init__(self, patch_dim: int, d_model: int): #linear projection
super().__init__()
self.proj = nn.Linear(patch_dim, d_model)
def forward(self, x_patches: torch.Tensor) -> torch.Tensor:
"""Project flattened patches from patch_dim to d_model."""
return self.proj(x_patches)
class PositionalEmbedding(nn.Module):
def __init__(self, num_tokens: int, d_model: int):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, d_model))
self.pos_embed = nn.Parameter(torch.zeros(1, num_tokens + 1, d_model))
#fill this tensor with values from a normal distribution, but truncate extreme values.
#std=0.02 means the random values are very small, close to zero
nn.init.trunc_normal_(self.cls_token, std=0.02)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Prepend the class token and add learned positional embeddings."""
batch_size = x.shape[0]
cls_tokens = self.cls_token.expand(batch_size, -1, -1) #-1 means same dimension
#concatenate with the class token x.shape = (batch_size, num_patches + 1, d_model)
x = torch.cat([cls_tokens, x], dim=1)
return x + self.pos_embed[:, : x.shape[1], :] #position vectors are added to patches in the batch2. GLU vs FFN in transformer blocks
In Vision Transformers, we can also use the normal feed-forward multi-layer perceptron (MLP) block. GLU is an optional gated variant with a different activation-style path, and I am touching it briefly here for anyone who wants to read it. If not, you can skip this part.
A standard FFN usually looks like: linear up-projection, activation, then linear down-projection. GLU-style variants add a learned gating branch, so one branch can modulate the other element-wise. This gives better control of information flow and often improves training behavior.
The explainer compares standard FFN and GLU variants, and includes a parameter comparison view showing why models often use roughly 2/3 width for GLU while keeping a similar parameter budget.
Gated Linear Units (GLU) and variants
Gated Linear Units (GLU), a neural network layer defined as the component-wise product of two linear transformations of the input, one of which is sigmoid-activated. GLU(x, W, V, b, c) = σ(xW + b) ⊗ (xV + c) Bilinear(x, W, V, b, c) = (xW + b) ⊗ (xV + c) Additional Transformer FFN variants: FFN_GLU(x, W, V, W2) = (σ(xW) ⊗ xV)W2 FFN_Bilinear(x, W, V, W2) = (xW ⊗ xV)W2 FFN_ReGLU(x, W, V, W2) = (max(0, xW) ⊗ xV)W2 FFN_GEGLU(x, W, V, W2) = (GELU(xW) ⊗ xV)W2 FFN_SwiGLU(x, W, V, W2) = (Swish1(xW) ⊗ xV)W2 These layers use three weight matrices (vs two in standard FFN). To keep parameter count and computation approximately constant, hidden size d_ff is reduced by about 2/3 when comparing with the two-matrix FFN.
Source: Shazeer, 2020
In a GLU, the model splits the calculation into two parallel paths. One path determines "how important is this feature?" (the gate), while the other path calculates the feature values. By multiplying them element-wise, the model dynamically scales, routes, and amplifies important features while silencing noise on a token-by-token basis.
Open GLU mechanism explainer in a new tab
Show FFN baseline + GLU variants implementation (PyTorch)
# FFN baseline and GLU variants to compare in the Transformer blocks.
class FeedForward(nn.Module):
"""
Standard Transformer FFN:
x -> Linear(d_model->d_ff) -> GELU -> Dropout -> Linear(d_ff->d_model) -> Dropout
"""
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout), #dropping out some percent of neurons during the training phase
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
class GLUFeedForward(nn.Module):
"""GLU-family FFN: act(W_a x) * W_b x, followed by projection back to d_model."""
def __init__(self, d_model: int, d_ff_gated: int, dropout: float, variant: str):
super().__init__()
self.variant = variant.lower()
self.proj_in = nn.Linear(d_model, 2 * d_ff_gated) #self.proj_in(x).shape == (batch_size, tokens, 512)
self.dropout = nn.Dropout(dropout)
self.proj_out = nn.Linear(d_ff_gated, d_model)
valid_variants = {"geglu", "swiglu", "reglu", "glu"}
if self.variant not in valid_variants:
raise ValueError(f"Unknown GLU variant '{variant}'. Choose one of {sorted(valid_variants)}.")
def forward(self, x: torch.Tensor) -> torch.Tensor:
a, gate = self.proj_in(x).chunk(2, dim=-1) #split the tensor into two parts. take the last batch to GLU
#what GLU does activation(a) * gate
#activation functions
if self.variant == "geglu":
a = F.gelu(a)
elif self.variant == "swiglu":
a = F.silu(a)
elif self.variant == "reglu":
a = F.relu(a)
elif self.variant == "glu":
a = torch.sigmoid(a)
#proj_in -> split -> activation/gate multiply -> Dropout -> proj_out -> Dropout
x = a * gate
x = self.dropout(x) #drop hidden features before output projection
x = self.proj_out(x)
return self.dropout(x) #final out put of the MLP before residual addition3. Transformer encoder block (Pre-LN)
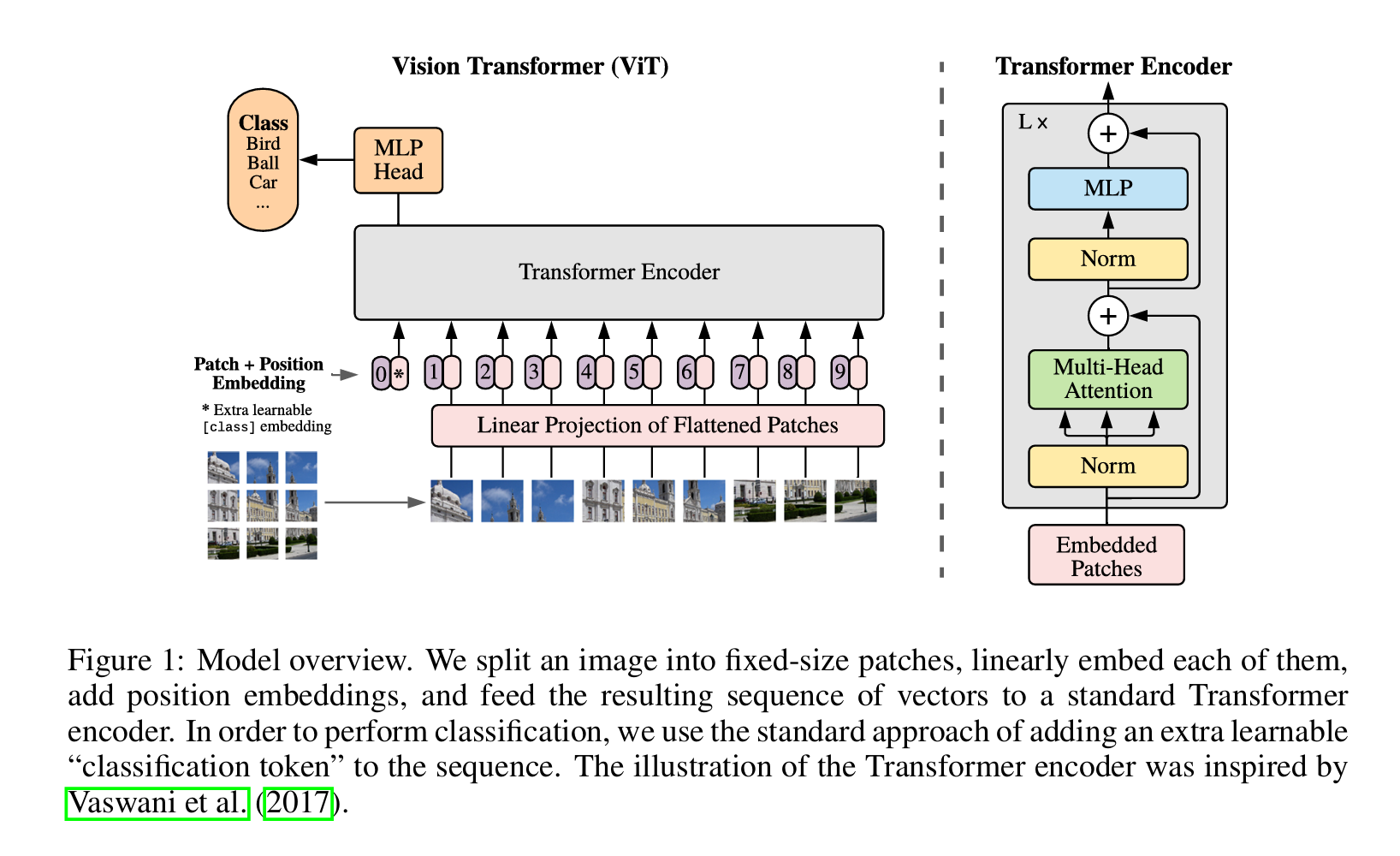
Source: Dosovitskiy et al., 2020 — "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale", Figure 1 (https://arxiv.org/pdf/2010.11929)
Show TransformerEncoderBlock implementation (PyTorch)
class TransformerEncoderBlock(nn.Module):
"""
Pre-LN encoder block: #LN means LayerNorm, normalizing across the feature dimension
x = x + Dropout(SelfAttn(LN(x)))
x = x + Dropout(MLP(LN(x)))
"""
#basically following the architecture of the paper
def __init__(self, d_model: int, n_heads: int, mlp: nn.Module, dropout: float):
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.attn = nn.MultiheadAttention( #nn.MultiheadAttention expects query, key and value
embed_dim=d_model,
num_heads=n_heads,
dropout=dropout,
batch_first=True,
)
self.dropout = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
self.mlp = mlp
def forward(self, x: torch.Tensor) -> torch.Tensor:
attn_input = self.norm1(x)
attn_out, _ = self.attn(attn_input, attn_input, attn_input, need_weights=False) #for query, key and value
x = x + self.dropout(attn_out)
x = x + self.mlp(self.norm2(x))
return xThe bigger picture
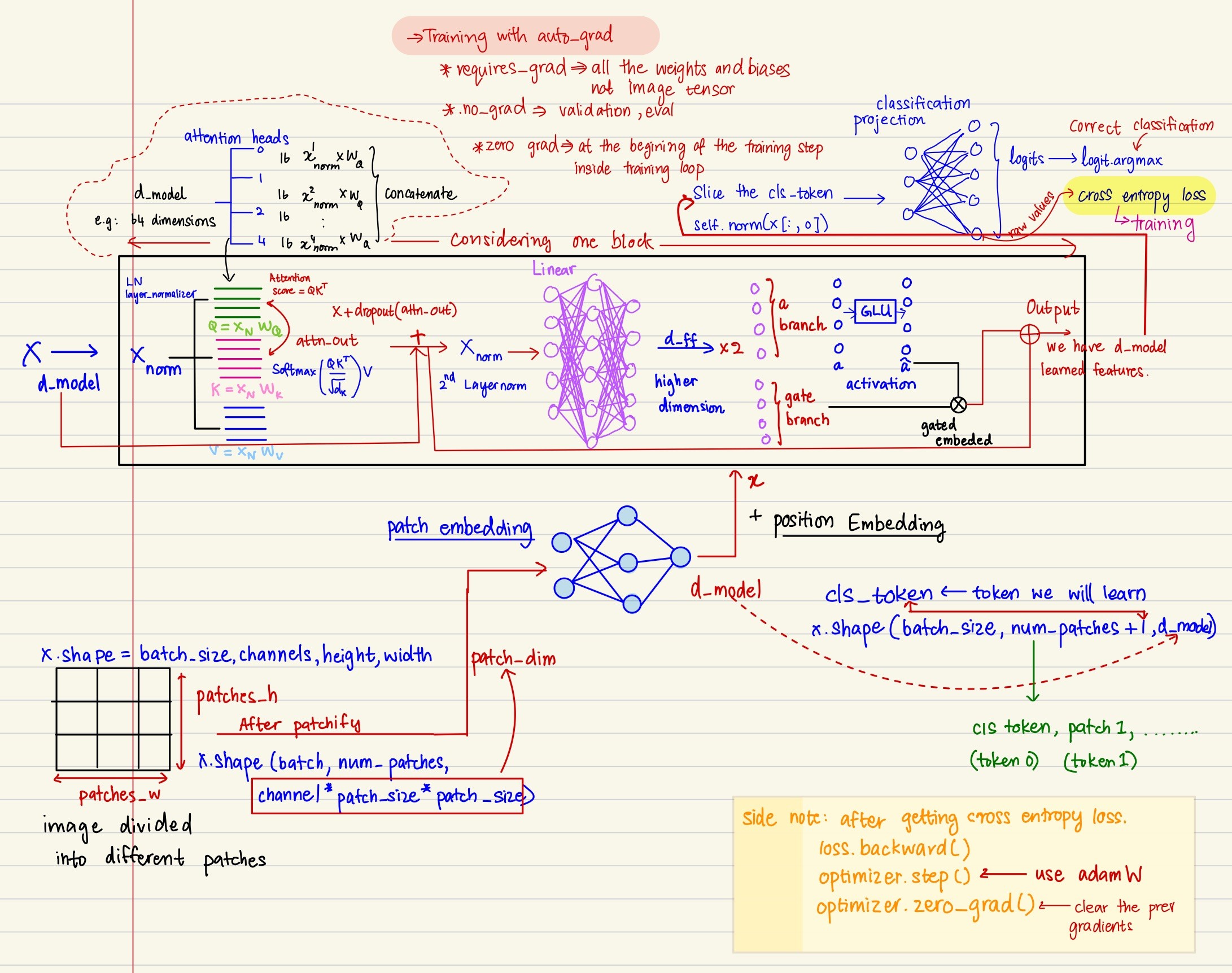
The results of developing a tiny ViT encoder are in this repo as well: ethz-course-2026 / ex4_README.md.